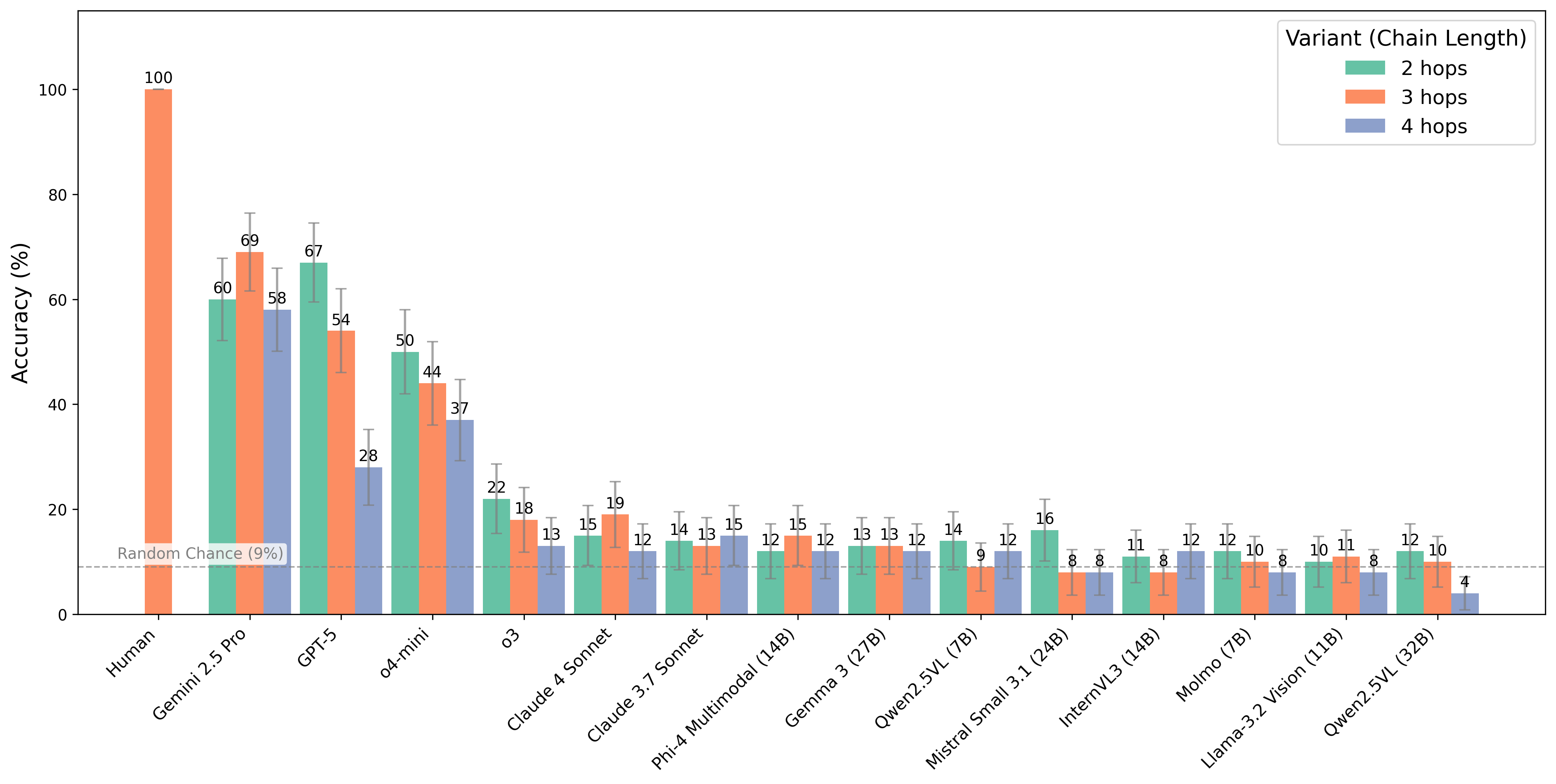
Comparative perception differs from general comparison because it occurs chiefly in the visual domain. The images must be close enough that it requires repeated examination to tell them apart. For instance, an image of a penguin and of Angkor Wat can be easily distinguished. We design "Object Re-Identification" to require this ability.
Comparative Perception
Object Re-Identification
Each instance of the task shows an object composed of multiple geometric shapes in Image 1. That same, globally transformed object is also shown in Image 2. The task is to determine if any of the component shapes have been transformed seperately from the object as a whole, making it a different object. We avoid imperceptible edits.
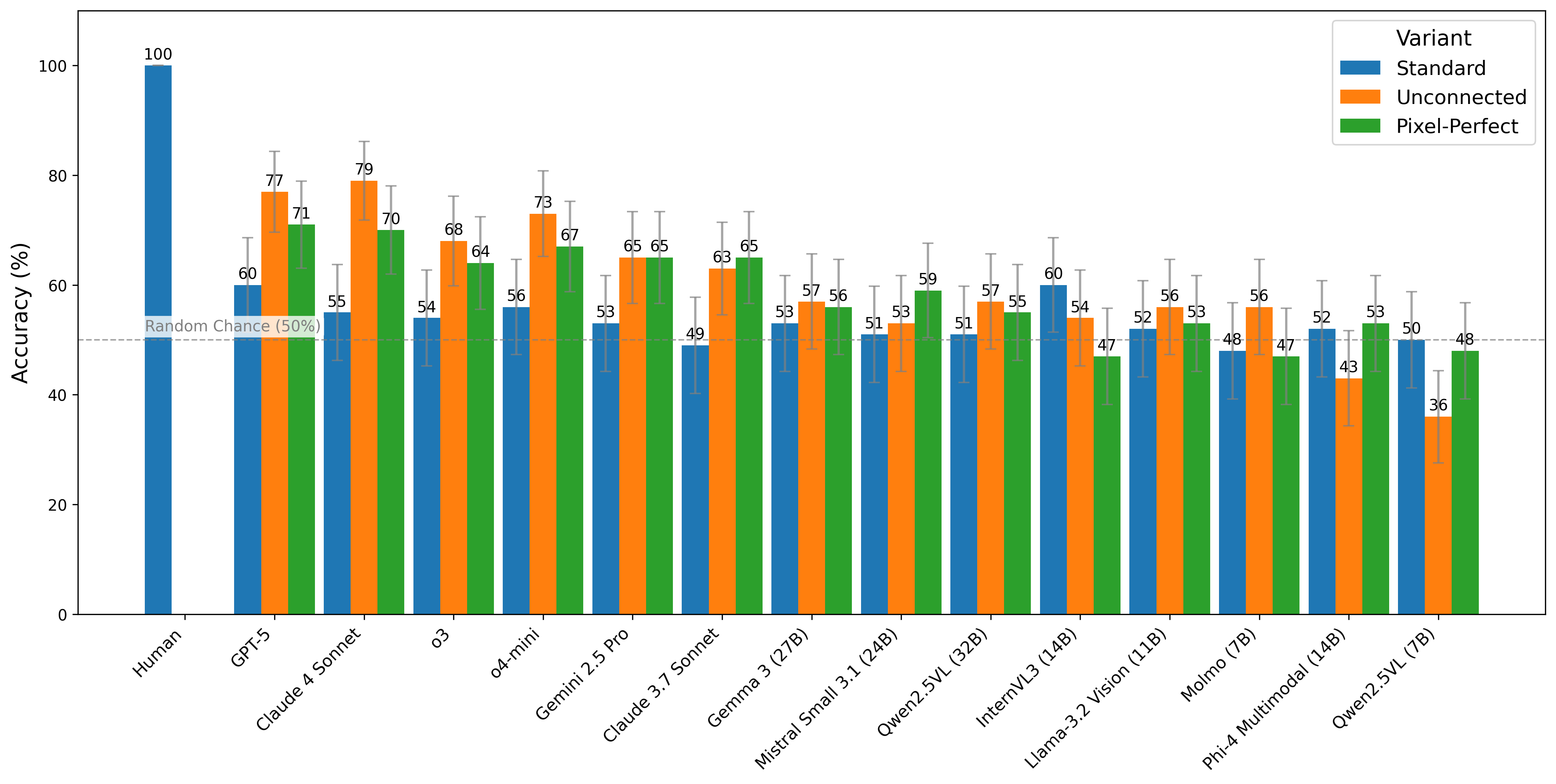
Presentation Variants
- Standard: all component shapes in the object touch.
- Unconnected: parts may float apart, probing the model's conception of an object.
- Pixel-Perfect: positive examples reuse Image 1 exactly, with no global transform. This can be solved through pixel-matching.
Example Task
Prompt: Decide whether the composite object from Image 1 is still present somewhere in Image 2, even though the scene may include distractors.
Image 1

This image defines the object to look for in Image 2.
Image 2

The object (green circle) has been rotated, but the three component shapes that compose it remain identically positioned relative to each other. The distraction object (in the red circle) can be ignored.
Answer: Yes
A visual skim is not enough to solve this task. Both images must be compared carefully.
Try it yourself
Image 1
Image 2
Determine whether the object from Image 1 reappears in Image 2, or if it is corrupted.
Select an answer to see how you compare.
Results